Claude Code ソースコード解説シリーズ 第1章: アーキテクチャ
Claude Code のランタイムアーキテクチャ、能力レイヤー、主要モジュールを俯瞰します。
『Claude Code ソースコード解析シリーズ』第1章|エンジニアリングアーキテクチャ
Claude Code を初めて見た人の多くは、「コードを書けるチャットボックス」と理解するだろう。
その理解は間違いではないが、あまりにも表面的だ。Claude Code の本当に優れた点は、モデルがコードの質問に答えられることだけではない。モデルの外側に、プロジェクトを読み取り、ツールを呼び出し、コンテキストを維持し、状態を管理し、MCP に接続し、サブエージェントをディスパッチし、さらに権限とセキュリティ境界を守るという、一連のエンジニアリングシステムが組み上げられているのだ。
そのため本章では、いきなり特定のソースコード関数に飛び込むのは後回しにして、まずより大きな問いに答えていこう。
Claude Code とは、一体どのようなエンジニアリングアーキテクチャなのか?
一言で表すなら、こうだ。
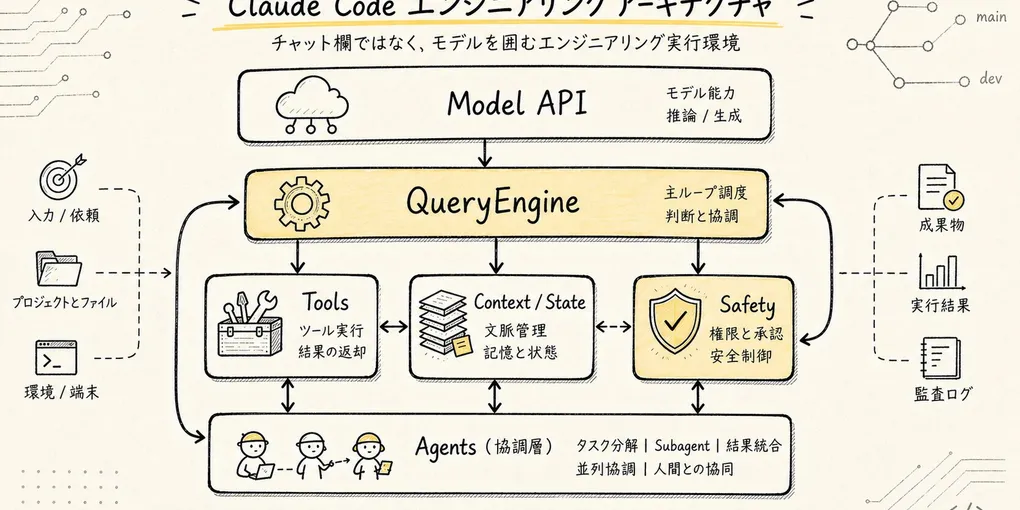
Claude Code = Model API + QueryEngine メインループ + Tools システム + Context/State 管理 + セキュリティガバナンス + Agent コラボレーション。
モデルは推論能力の中核に過ぎない。「実際に仕事をするプログラミングエージェント」へと変貌させるのは、モデルの外側を取り巻くランタイム全体なのである。
このことを明らかにするために、以下3つの問いに沿って見ていこう。
- 機能アーキテクチャ:どのような能力層があるのか?
- 実行アーキテクチャ:ユーザーの一言がシステム内でどう流れるのか?
- コードアーキテクチャ:ソースコードは大まかにどのようなモジュールで構成されているのか?
この3つの問いは段階的に深まっていく。まず Claude Code にどのような能力があるかを知り、次にそれらの能力が QueryEngine によってどう結びつけられるかを理解し、最後にソースコードに戻って、それぞれがどのモジュールに対応するかを見ていく。
1. Model API を直接使うだけでは不十分な理由
最もシンプルな AI プログラミングアシスタントを想定すると、フローは次のようになります。
ユーザーが質問を入力
→ バックエンドが質問を大規模モデルに送信
→ 大規模モデルが回答を返す
→ ユーザーに表示これは「コードの一部を解説して」程度であれば、なんとか対応できます。しかし、ユーザーが次のように言った瞬間:
このプロジェクトでテストが失敗している原因を調べて、修正してくれない?事態は一気に複雑になります。
モデルはまずプロジェクト構造を把握し、どのようなファイルがあるか、テストコマンドの実行方法、エラーログの場所、どのファイルを修正すべきかを知る必要があります。修正後は再度テストを実行して検証しなければなりません。途中で権限の問題、コマンドの失敗、コンテキスト長の超過、ツール出力の過大といった問題に遭遇すれば、そこから回復する必要もあります。
モデルは思考することはできても、実際のエンジニアリング環境に自ら触れることはできません。
モデルは本来的にファイルを読み取れず、Shell を実行できず、長期的なタスク状態を維持できず、どの操作が危険かを知ることもできません。そのため、Claude Code は Model API の外側に「エンジニアリングシェル」を重ねる必要があります。
このエンジニアリングシェルこそが、Claude Code のコアバリューです。
多くのオープンソース Agent プロジェクトはここで行き詰まります。モデル呼び出しはうまく作れても、エンジニアリングシェルは少し触れただけで穴だらけになるのです。
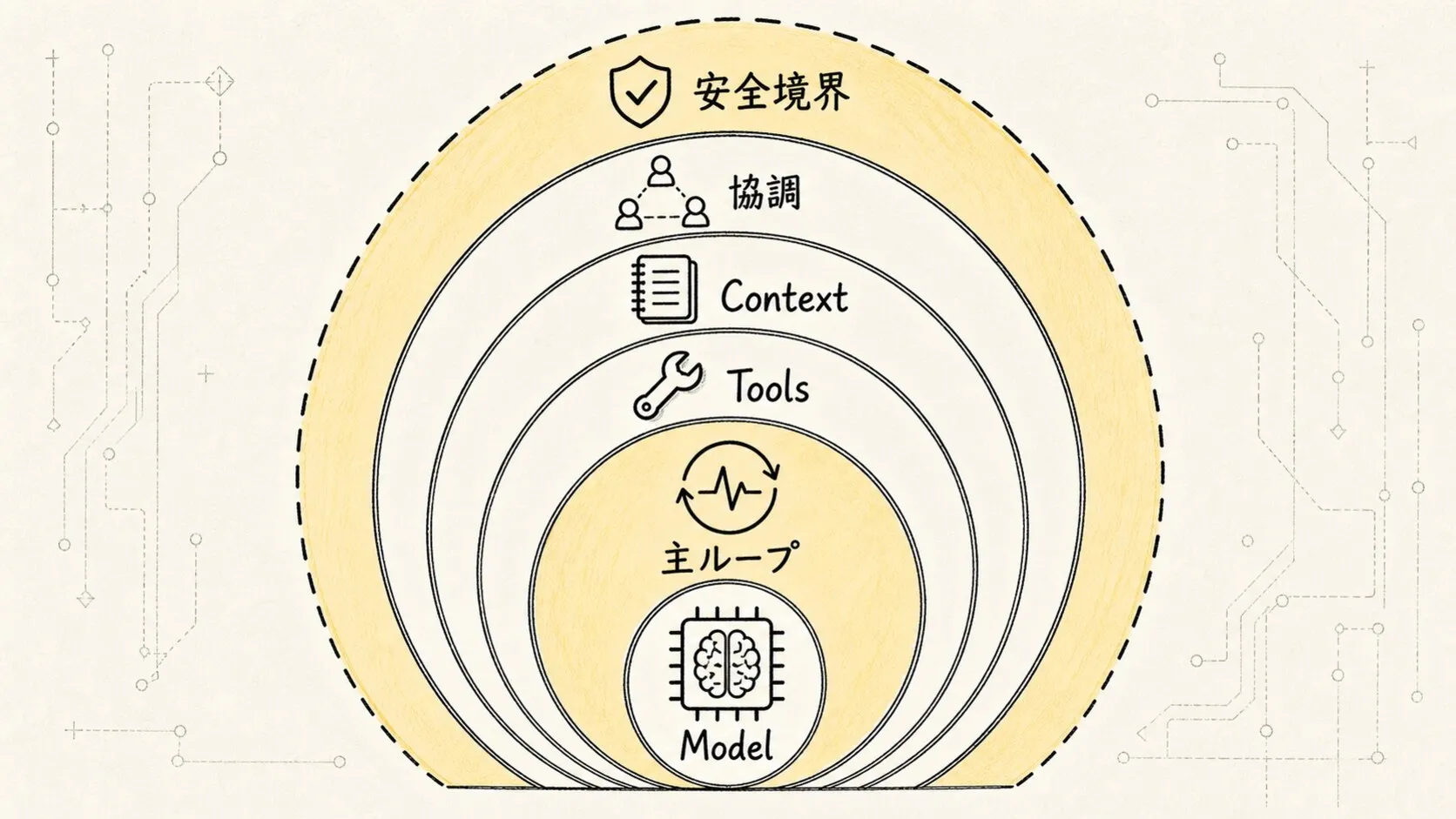
2. 機能アーキテクチャ:Claude Code にはどのような能力層があるか?
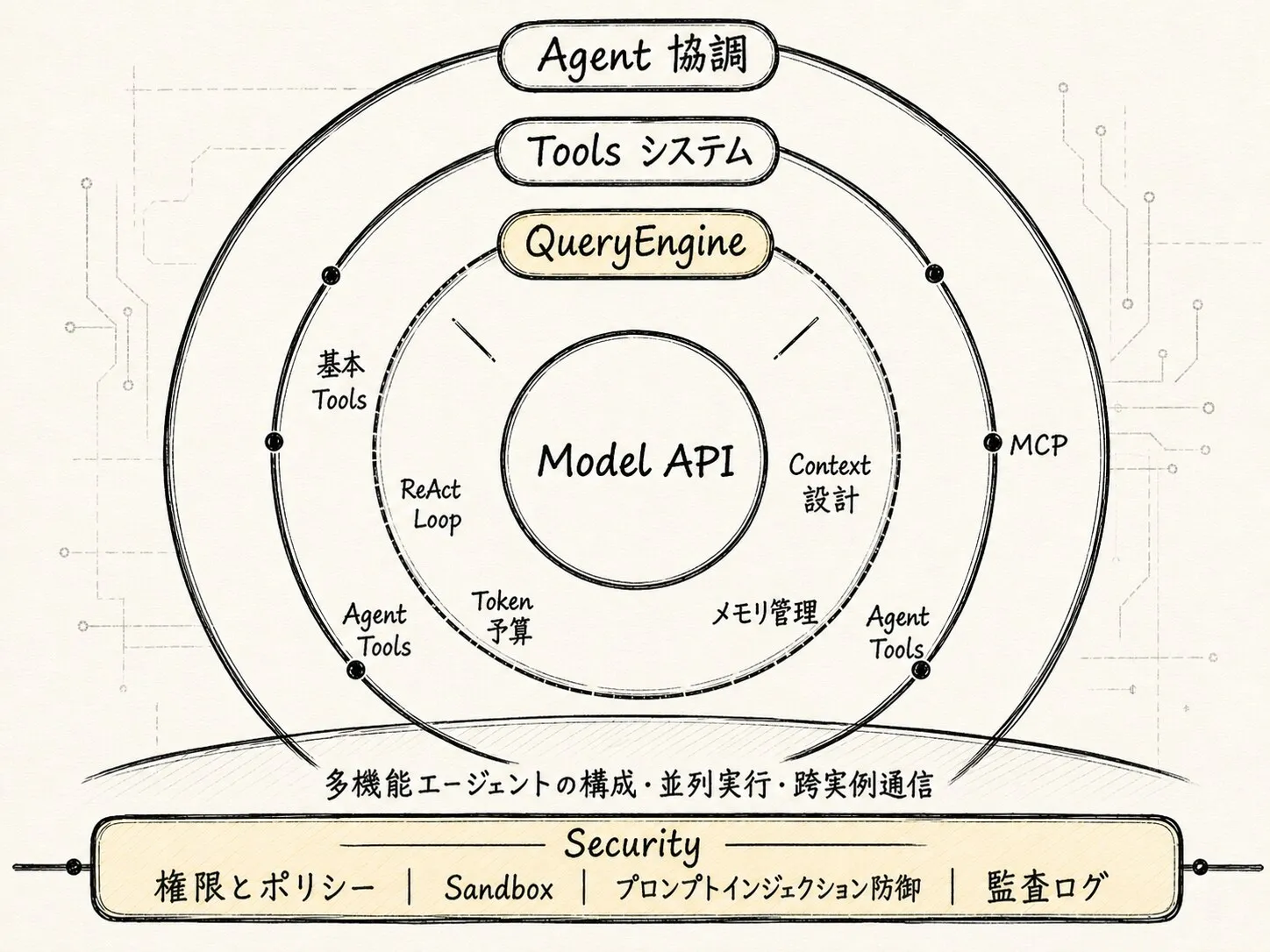
機能アーキテクチャの観点から見ると、Claude Code は何層にも包まれた Agent Runtime(モデルを中心に構築されたエージェント実行環境。ツールのスケジューリング、状態管理、タスクの推進を担う)のような構造を持つ。
最も内側にあるのが Model API。推論の中核であり、タスクの理解、回答の生成、次のステップでツールを呼び出すかどうかの判断を担う。ただし、これはあくまで「頭脳」であり、完全なシステムではない。
モデルを取り巻く最初の層が QueryEngine(クエリエンジン。一度のユーザー入力を、継続的に動作する Agent メインループへと変換する責務を負う)。QueryEngine がなければ、Claude Code は単なる API ラッパーに過ぎない。QueryEngine があるからこそ、タスクを継続的に推進できるランタイムへと姿を変える。
その外側にあるのが Tools システム。この層はモデルに「手足」をつなぐ。ファイルの読み書き、シェルコマンド、検索、Web、MCP、LSP、Agent ツール、Skills はいずれもこの層に属する。
さらに外側が Context / Memory / State。この層が解決するのは「モデルは今回のターンでいったい何を知っておくべきか」という問題である。システムプロンプト、ユーザー入力、プロジェクトルール、過去のメッセージ、ツールの実行結果、ファイルキャッシュ、圧縮された要約、現在のアプリケーション状態を動的に組み立てる。
さらに外側は エージェント連携。タスクが複雑化した場合、Claude Code は単にモデルと単一スレッドで対話するだけでなく、特定のサブタスクを Agent / Task に切り出して処理させることができる。メイン Agent が全体の判断を担い、サブ Agent がコード検索、方針の検討、仮説の検証を担当する。
最も外側の層は、すべての能力を横断するセキュリティガバナンスである。Claude Code が扱うのは現実のエンジニアリング環境であり、プライベートなコードの読み取り、コマンドの実行、ファイルの変更、外部サービスの呼び出しが発生しうる。権限制御、ポリシー、サンドボックス、プロンプトインジェクション対策、監査ログがなければ、Agent が強力であるほどリスクは増大する。
この図で理解してほしい:
この図が最も伝えたいのは「Claude Code にはモジュールが多い」ということではない。伝えたいのは次の一点である。
Claude Code の能力は、モデルから直接生えているのではなく、モデルの外側に構築された一層一層のエンジニアリングシステムから生えている。
Model API:判断を担い、実行は担わない
まず最も混同されやすい点を明確にしておく。Model API はどんなツールも直接実行しない。
モデルが実際に出力するのは、次のような意図である。
あるファイルを読み取る必要がある。
あるキーワードを検索する必要がある。
テストコマンドを実行する必要がある。
あるコードブロックを修正する必要がある。しかし「ファイルを読み取る」「コマンドを実行する」「コードを修正する」といったアクションは、すべて Claude Code のホストプログラムが実行する。
役割分担は明確だ。
モデルは理解・計画・選択を担う。
プログラムは実行・制約・記録を担う。あらゆる能力をモデル自身の魔法のように捉えてしまうと、Claude Code の本質的な価値が見えなくなる。Claude Code が本当に学ぶに値するのは、まさに「知的ではないが極めてエンジニアリング的」な部分——ツール契約、権限システム、状態管理、コンテキスト圧縮、エラーリカバリ、UI レンダリング、セッション記録——である。
QueryEngine:システム全体の心臓
QueryEngine は Claude Code のメインループである。
その責務は単に「モデルにリクエストを送る」ことではなく、セッションのライフサイクル全体を管理することだ。ひとつのセッションには、複数回のユーザー入力、複数回のモデル応答、複数回のツール呼び出し、複数回の状態変化が含まれる。QueryEngine はこれらをすべてつなぎ合わせる。
QueryEngine が保持すべき状態には、少なくとも以下が含まれる。
- 現在のメッセージ履歴
- 現在の作業ディレクトリ
- 現在利用可能なツールセット
- 現在のモデルと予算
- ファイル読み取りキャッシュ
- 権限拒否の記録
- Skill 検出の記録
- トークン使用量
- セッショントランスクリプト
これらの状態が、Claude Code が次にどのように行動すべきかをまとめて決定する。
(QueryEngine の実装詳細は次章で詳述するが、本質的にはステートマシンである。各ラウンドで現在の状態に基づいて次に何をすべきかを決定し、実行後に状態を更新する。)
Tools システム:モデルの手足、ただし制御下に置く
Claude Code のツールシステムは、統一された能力のマーケットプレイスとして理解できる。
その中には基本ツールが含まれる。
Read / Write / Edit / Grep / Glob / Bash拡張機能もあります:
MCP / LSP / Web / Agent / Skillツールシステムにおいて最も重要なのは「ツールの数が多いこと」ではなく、すべてが統一されたツールコントラクトに従っていることです。各ツールは次のような問いに答える必要があります:
- このツールの名前は?
- 入力パラメータは?
- 入力の検証方法は?
- 実行方法は?
- 出力をどうメッセージに戻すか?
- 読み取り専用か?
- 破壊的操作か?
- 並列実行を許可するか?
- ユーザー確認が必要か?
これこそが、Claude Code が「モデルにシェルコマンドを自由に書かせる」アプローチより工学的に洗練されている点です。
たとえば同じファイルを見る操作でも、モデルに直接実行させる場合:
cat src/main.tsもちろんこれでも動作はします。しかし、システムがこの操作の本当の意味を把握することは困難です。単なるシェル文字列に過ぎません。
一方、Read ツールを経由すれば、Claude Code は次のことを知ることができます:
これは読み取り操作である
対象パスは何か
権限を逸脱していないか
出力が大きすぎないか
切り詰めが必要か
ファイルキャッシュに載せるべきか
後続の Edit は最新バージョンに基づいているかこれがツール抽象化の価値です:
ツールはモデルに「より多くのことをさせる」ためではなく、モデルの行動を理解可能・制限可能・監査可能にするためにあるのです。
Context / Memory / State:モデルに知るべきことを知らせる
Claude Code のもう一つの過小評価されがちな力が、コンテキストエンジニアリングです。
コンテキストと聞くと、多くの人は「プロンプトを長く書くこと」を思い浮かべます。しかし Claude Code において、コンテキストは静的なテキストではなく、毎ターン動的に組み立てられるランタイム入力です。
含まれうる要素:
- ベースの system prompt
- 現在のユーザー入力
- 過去のメッセージ履歴
- プロジェクトレベルのルール
- ユーザーレベルのルール
- 現在の作業ディレクトリ
- 利用可能なツールの説明
- MCP / LSP が公開する外部機能
- Skill の説明
- ファイル読み取り結果
- 直前のツール実行結果
- 圧縮された履歴サマリ
- 現在の AppState
ここで本当に難しい問題が二つあります。
一つ目は「何を与えるか」。 少なすぎればモデルは背景を把握できず、多すぎればコンテキストが爆発し、コストとレイテンシが制御不能になります。
二つ目は「いつ与えるか」。 ある情報は最初から system prompt に入れるべきであり、ある情報はモデルが必要とした時点でツール経由で読み取るべきであり、一部のツールスキーマは遅延発見に任せて、一度にすべてを詰め込まない方が良いのです。
率直に言うと:
Context Engineering はプロンプトライティングではなく、コンテキストのスケジューリングである。
Memory / Compression が解決するのは長時間タスクの問題だ。実際のエンジニアリングタスクでは、コード検索、ファイル読み取り、テスト実行、エラー分析、コード修正、再テストといったサイクルが頻繁に発生する。各ステップでメッセージとツール実行結果が生成される。これらをそのままモデルに送り返すと、コンテキストはすぐに肥大化し、混乱してしまう。
圧縮機構の価値は単なるトークン節約ではなく、長時間タスクにおいてエージェントが主線を見失わないようにすることにある。
AppStateStore は、CLI UI、セッション状態、ツール状態、エージェント状態を統一的に管理する責務を担う。たとえば、現在 Plan Mode か否か、利用可能な MCP ツールは何か、現在の権限モードは何か、バックグラウンドタスクが走っているかどうか──これらはモデルメッセージだけでは解決できず、アプリケーション状態管理システムを必要とする。
MCP / LSP / Skills:拡張機能の接続レイヤー
Claude Code はあらゆる機能をメインプログラムに内蔵できるわけではない。ゆえに拡張機構が必要となる。
MCP(Model Context Protocol:外部ツールやリソースをエージェントが標準化された形で呼び出せるようにするプロトコル)は、より外部ツールプロトコルに近い位置づけだ。Claude Code が外部サービス提供のツールやリソースを発見・呼び出せるようにする。データベース、ブラウザ、デザインツール、内部システムなど、いずれも MCP を通じてエージェントから呼び出し可能なケイパビリティに変わる。
LSP(Language Server Protocol:シンボル、定義、参照などのコード意味情報を提供するプロトコル)は、コードインテリジェンス寄りだ。Claude Code がプログラミング言語そのものをより深く理解するための基盤となる。
Skills は、再利用可能なタスクメソッドパックに近い。通常は単一の API ではなく、特定のタスク種別に遭遇した際にエージェントが取るべき手順を示す、説明・スクリプト・テンプレート・トリガールールのセットである。
この三者は異なる問題を解決する:
MCP :外部ケイパビリティをどう標準化して接続するか
LSP :コード意味ケイパビリティをどう接続するか
Skills:再利用可能な作業メソッドをどうロードするかこれら三つが合わさって Claude Code の拡張レイヤーを構成している。
(実際に接続する際の落とし穴として、MCP ツールのスキーマが大きすぎるとコンテキストを直接圧迫する。Claude Code はこれを遅延ディスカバリーで対処している。一度にすべてを詰め込んだりはしない。)
セキュリティガバナンス:エージェントが有能であるほど、境界が必要になる
セキュリティレイヤーは装飾ではない。Claude Code がエンジニアリングツールとして成立するための前提条件である。
セキュリティレイヤーが扱う問題は大きく四つに分類される:
権限とポリシー:どのツールを使えるか、どのパスにアクセスできるか、どのコマンドに確認が必要か。
サンドボックス機構:危険な操作を制御可能な環境内に封じ込める。
プロンプトインジェクション対策:プロジェクトファイルや外部コンテンツによってモデルが権限外の行動を取らされるのを防ぐ。
監査ログ:モデルが何をしたか、ツールが何を実行したか、ユーザーが何を承認したかを記録する。ここで最も重要な設計思想は次のとおりである:
モデルは行動を提案できるが、システムの境界を迂回して直接行動することはできない。
モデルが出力する tool_use(モデルが特定のフォーマットでツール呼び出しを要求する行為)は、あくまでリクエストの発行に過ぎない。実際に実行される前には、必ずツールシステムと権限システムを通過する。
これこそが Claude Code と多くの玩具的なエージェントとの分水嶺である。玩具的なエージェントは「動くこと」を目指すが、プロダクションレベルのエージェントは「制約の下で動くこと」を目指さなければならない。
3. 実行アーキテクチャ:ユーザーの一言はシステム内でどう流れるか?
機能レイヤーを理解したところで、次は実行アーキテクチャを見ていこう。
ユーザー視点では、プロセスは一言で表せる。
ユーザー:このバグを直してしかし、Claude Code の内部では、この一言がそのままモデルに送られるわけではない。まず QueryEngine によってスケジューリングされるランタイムに渡される。
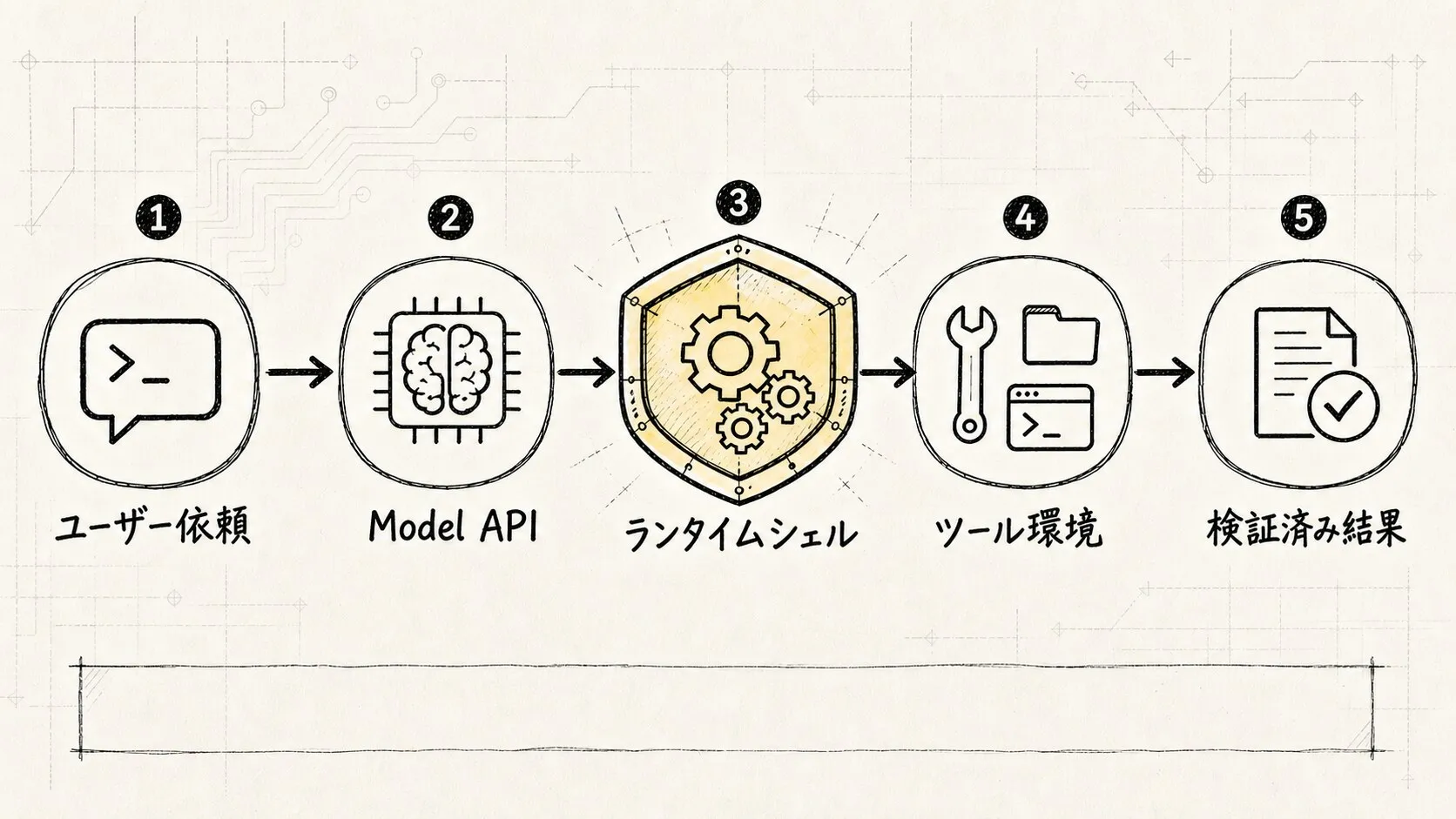
簡略化した実行フロー:
ユーザー入力
-> Claude Code セッション
-> QueryEngine.submitMessage()
-> ユーザー入力とスラッシュコマンドの処理
-> コンテキストとシステムプロンプトの構築
-> Model API 呼び出し
-> モデルがテキストまたは tool_use を返す
-> ツールシステムが権限をチェックしツールを実行
-> ツール結果をメッセージ履歴に書き戻す
-> QueryEngine が次のラウンドへ
-> タスク完了またはユーザー判断が必要になるまで繰り返し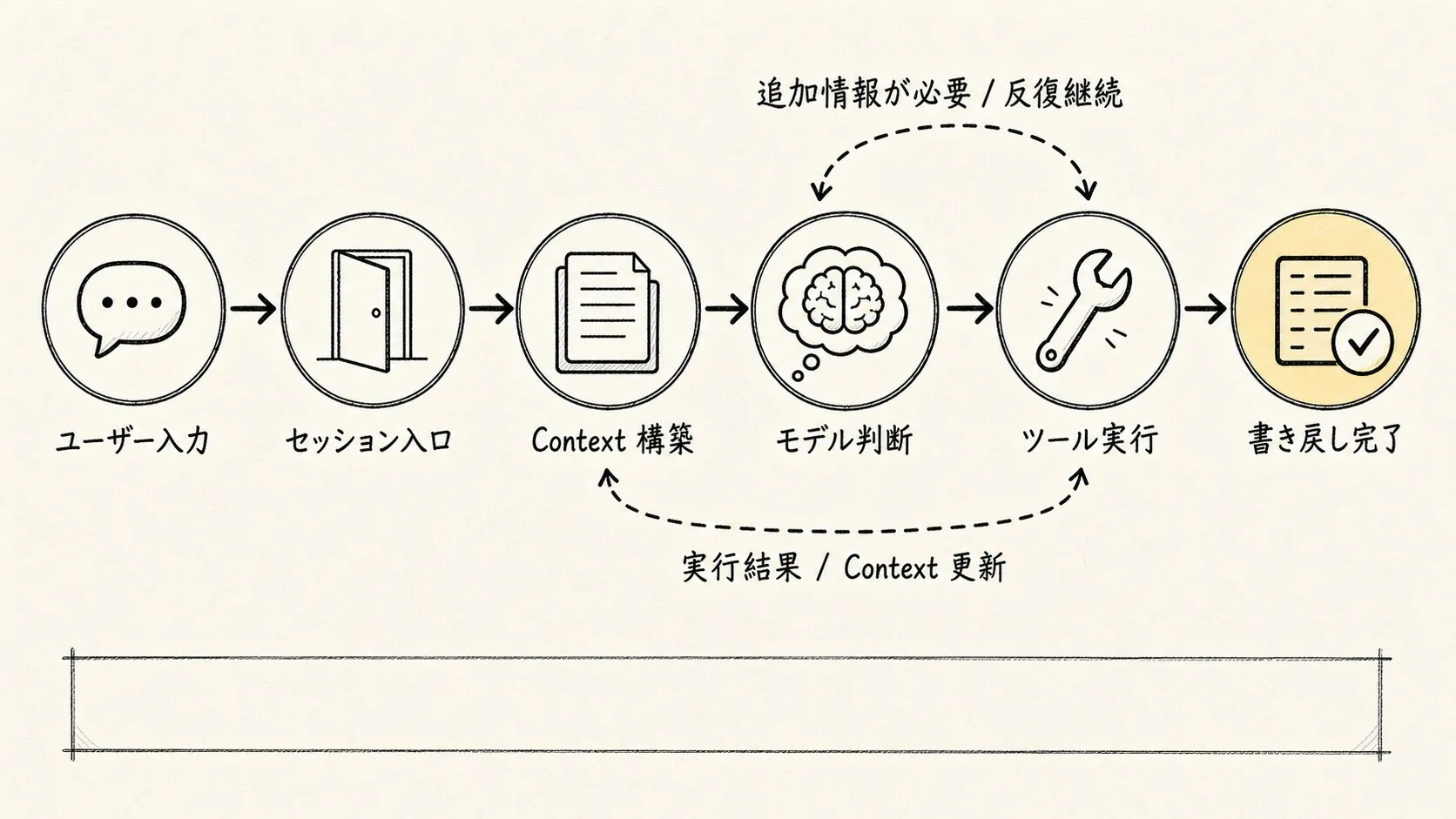
シーケンス図で表すと:
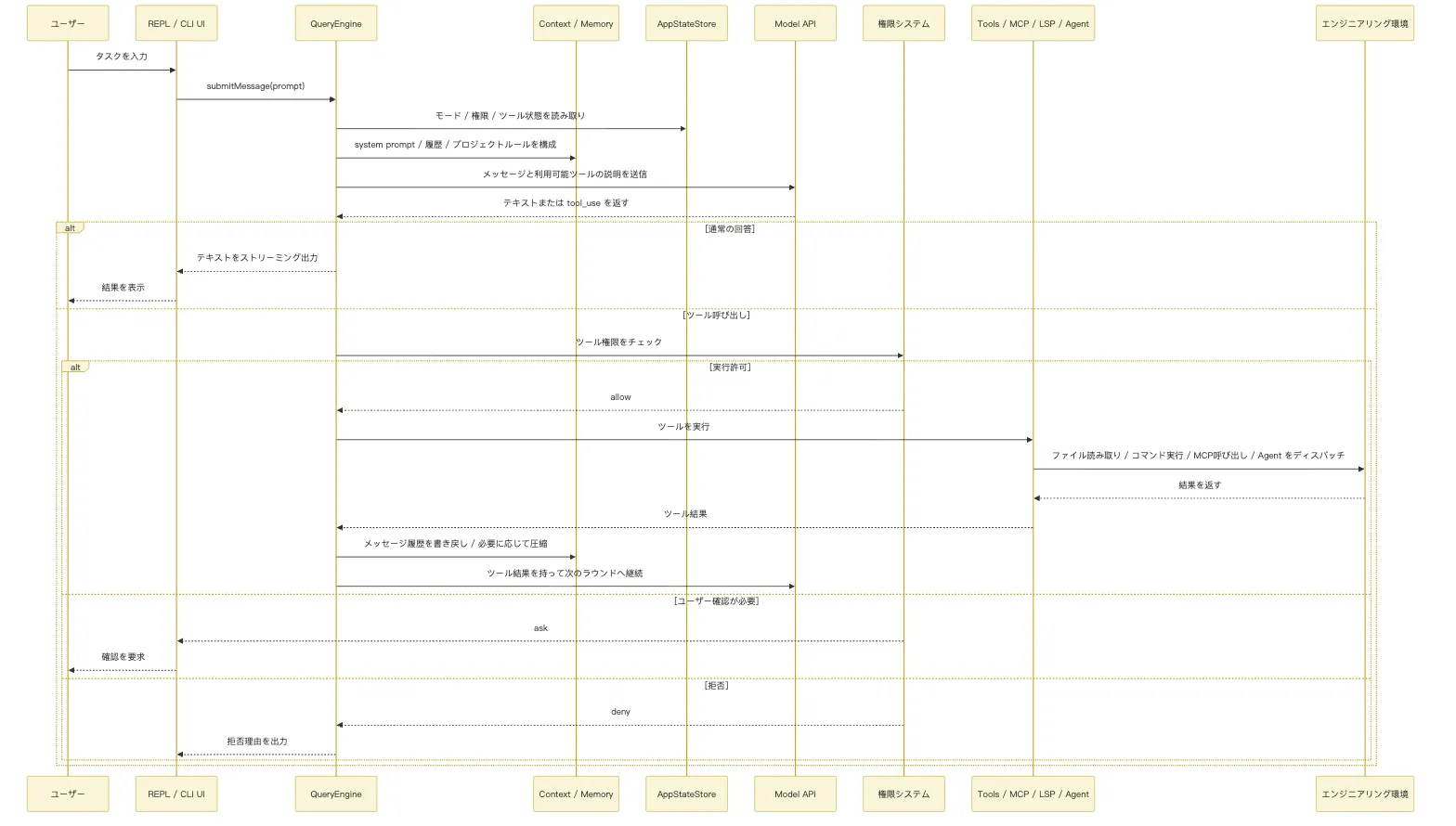
この図には二つのループがある。
一つ目はモデルとツール間のループ:
モデルが次の一手を判断
-> ツールが実際のアクションを実行
-> ツール結果がモデルに戻る
-> モデルがさらに判断を続けるこれこそが、Claude Code がタスクを連続的に進められる理由だ。
二つ目はコンテキストと状態間のループ:
毎ラウンドの実行がメッセージ履歴、ツール結果、権限状態、タスク状態を変化させる
-> 次のラウンドで QueryEngine はこれらの変化に基づいてコンテキストを再構築するこれが、Claude Code が単なる「一問一答」ではない理由だ。むしろ、継続的に動作するステートマシンに近い。
スラッシュコマンドは必ずしもモデルに届くとは限らない
実行アーキテクチャにはもう一つ細かい点がある。すべてのユーザー入力が Model API を呼び出すわけではない、ということだ。
設定、クリーンアップ、圧縮、状態確認など、一部の入力はローカルコマンドである。こうしたコマンドまで強制的にモデルを通すと、トークンを浪費するだけでなく、動作も不安定になる。
そのため、QueryEngine はユーザー入力を処理する際、まず次の判定を行う:
これはモデルの推論が必要なタスクなのか? それともローカルで直接実行できるコマンドなのか?
ローカルコマンドであれば、システムはその場で結果を返し、そのターンを早期に終了できる。
(この設計は実用的だ。たとえば /clear で画面をクリアする操作までモデルを往復していたら、体験はかなり悪くなる。)
Plan Mode で実行をまず立ち止まらせる
実行アーキテクチャにはもうひとつ重要なモードがある。Plan Mode だ。
通常のチャットプロダクトであれば、モデルがそのまま回答すればよい。しかしプログラミング向けAgentにとって、「いきなり手を動かす」ことにはリスクが伴う。ファイルを書き換えたり、コマンドを走らせたり、プロジェクトの状態に影響を与えうるからだ。
Plan Mode の意義は、タスクをふたつのフェーズに分けることにある。
まず理解と計画
それから実行と修正この背後にあるのは、Claude Code における制御権の設計思想だ。
- すべてのタスクが即時実行されるべきではない。
- すべてのツールがデフォルトで開放されるべきではない。
- ユーザーは重要な局面で計画を確認し、続行するかどうかを判断できるべきだ。
成熟したAgentシステムは、単に「自動化の度合いをどこまでも高める」ことを目指したりはしない。本当に難しいのは、自動化と制御性のあいだでバランスを取ることだ。
4. コードアーキテクチャ:ソースコードはどのようなモジュールで構成されているか?
最後にコードアーキテクチャに戻る。
機能アーキテクチャが「Claude Code にはどんな能力があるか」に答え、実行アーキテクチャが「それらの能力がどう連携して動くか」に答えるものだとしたら、コードアーキテクチャが答えるのは次の問いだ。
ソースコードを読むとき、最初にどういう地図を頭に入れるべきか?
ここでソースコードリーディングのコツを一つ紹介したい。まずはディレクトリツリーを横に舐めるように読まないことだ。Claude Code のソースディレクトリは多く、components、services、tools、hooks、utils と、どれも簡単に読者を迷子にしてしまう。より確実な方法は、まず「荷重連鎖(load-bearing chain)」を掴むことだ。
エントリポイントがユーザー入力をセッションに渡す
-> QueryEngine がひとつの conversation を管理する
-> query.ts が ReAct をターンごとに進行させる
-> Tool プロトコルがモデルの意図を実行可能なリクエストに変換する
-> Context / Prompt がモデルが各ターンで何を見るかを決める
-> Permission / Hooks / State がアクションを実際に実行できるかを決める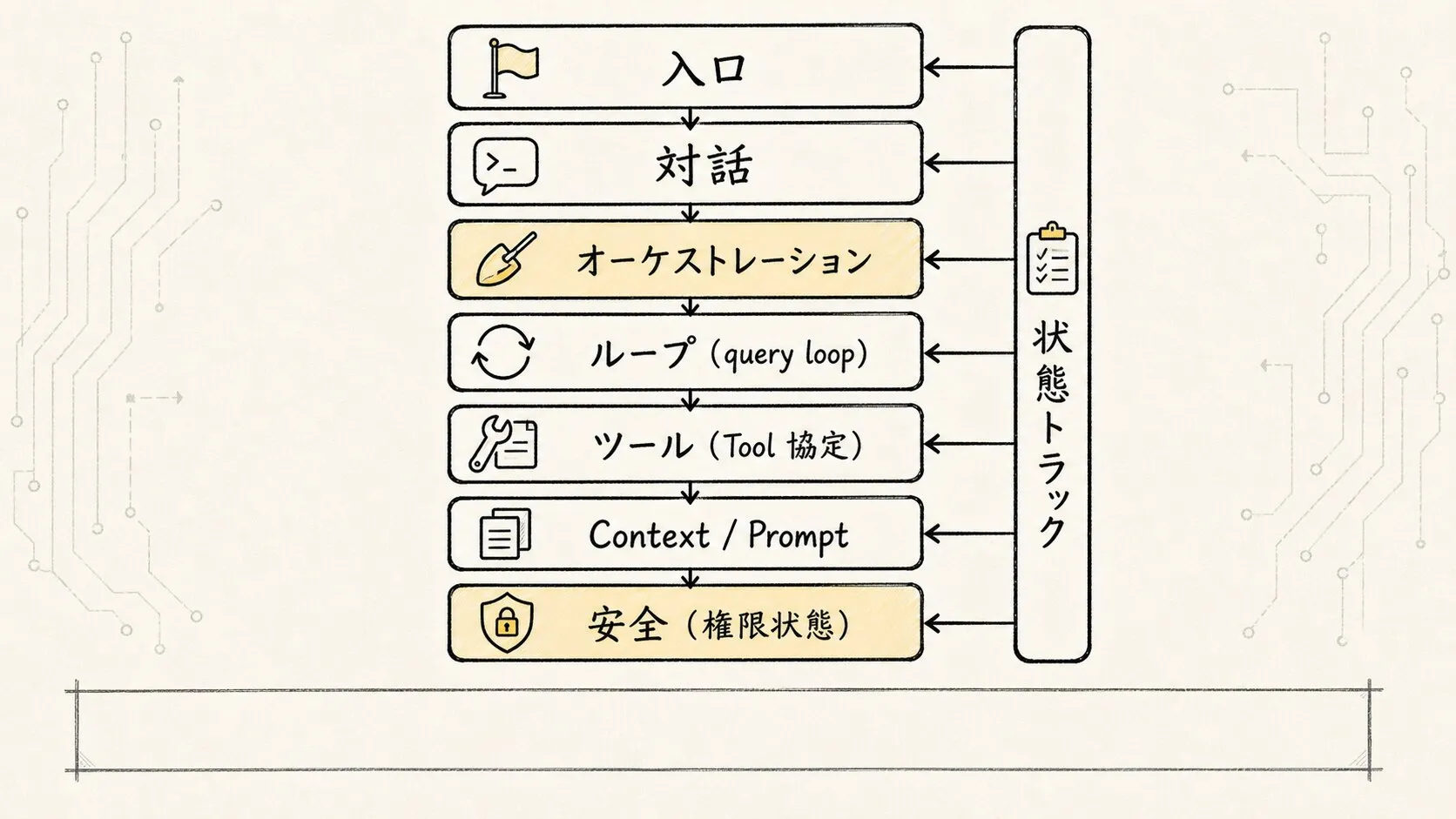
つまり、この節はディレクトリ一覧を示すのではなく、後続の記事群のためにソースコード上の座標を定めるものだ。
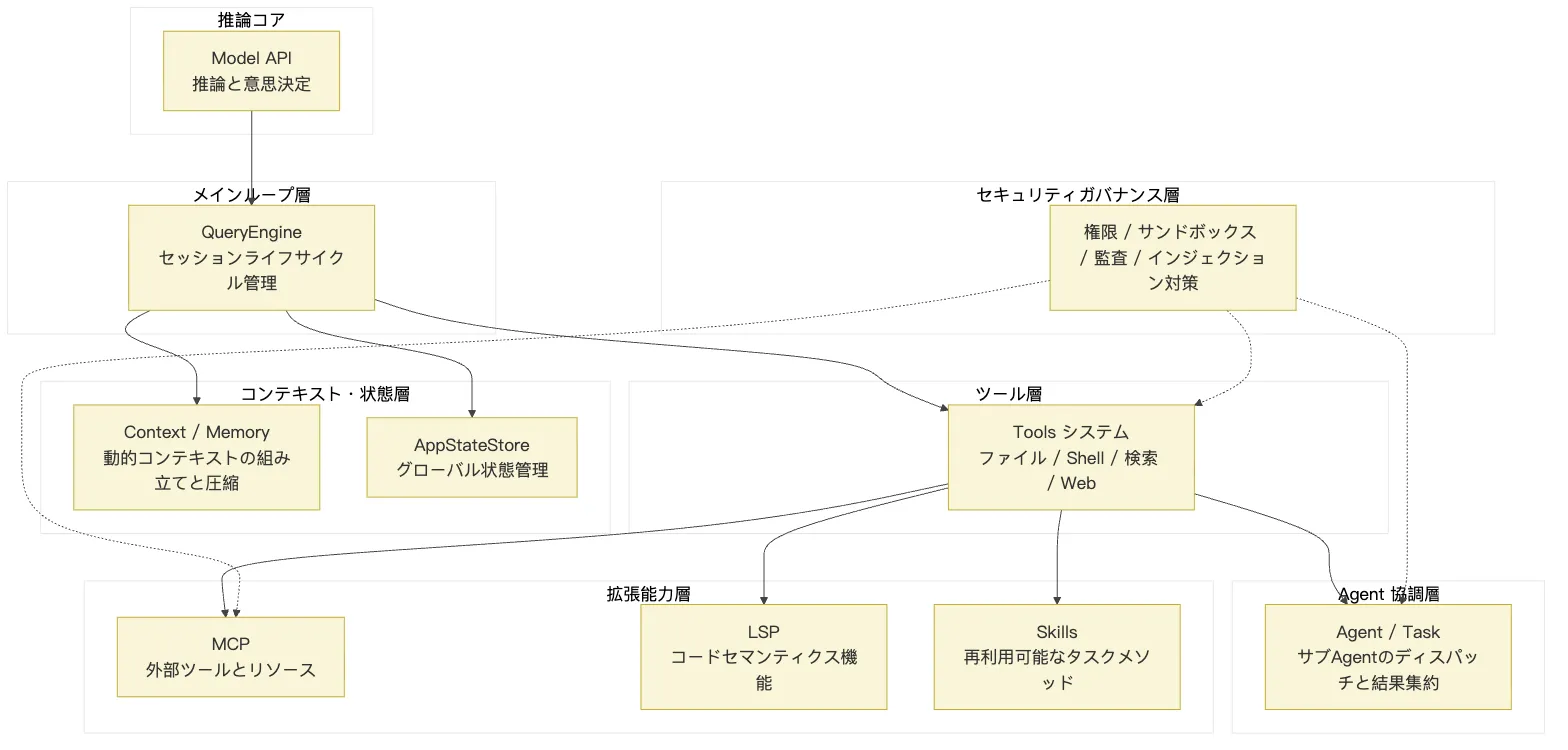
まずは以下の図で全体像を掴んでほしい。
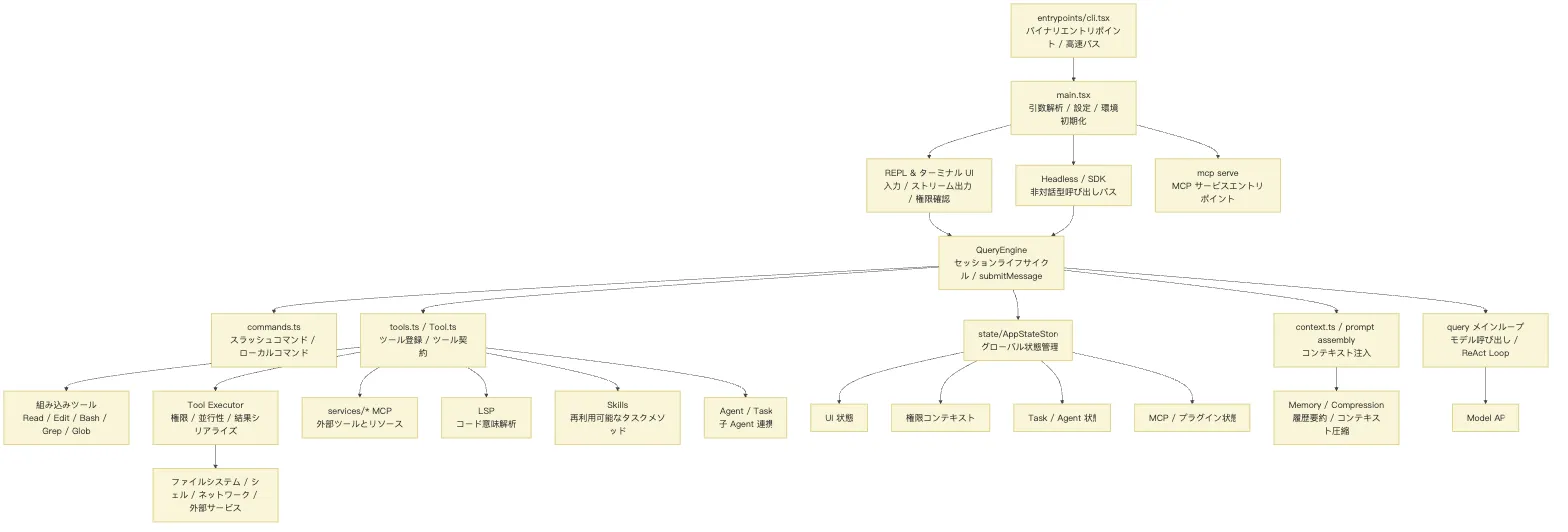
このコードアーキテクチャ図は、いくつかのレイヤーに分解して見ることができる。
エントリポイント層:cli.tsx と main.tsx
最上部にあるのは cli.tsx と main.tsx だ。
cli.tsx は実際のバイナリエントリポイントである。--version のようにアプリケーション全体をロードする必要のないコマンドなど、いくつかの高速パスを処理する。目的は CLI ツールの起動を可能な限り高速にすることだ。
main.tsx は本格的な起動フローに入り、コマンドライン引数、設定、環境変数、プリロード、モード分岐を担当する。プログラムを以下のように異なる実行パスへと導く。
インタラクティブ REPL
Headless / SDK
MCP サービス
その他のコマンドパスClaude Code は「ターミナルでのチャット」という形態だけではない。REPL、SDK、MCP サービスはいずれも基盤となる能力を共有できる。
インタラクション層:REPL とターミナル UI
Claude Code は CLI 製品であり、ターミナル UI は単なる付属物ではない。
この層が扱うもの:
- ユーザー入力
- ストリーミング出力
- ツールの実行進捗
- 権限確認
- エラーメッセージ
- タスクステータスの表示
- Plan Mode のインタラクション
ソースコードに大量の UI レンダリングや状態購読ロジックが含まれているのもそのためだ。エージェントはバックグラウンドで動いているだけではなく、ユーザーはターミナル上でエージェントが今何をしているのかを理解できる必要がある。
オーケストレーション層:QueryEngine と query メインループ
QueryEngine はセッションレベルのオーケストレーション層である。
上は REPL / SDK と接続し、下は query メインループ、コンテキストシステム、状態システム、ツールシステム、コマンドシステムと接続する。
query メインループは、よりモデル呼び出しと ReAct Loop(モデルが推論と実行を交互に繰り返すアクションループパターン)に寄った層である。メッセージをモデルに送信し、モデルからの応答を受け取り、tool_use を識別し、ツールの実行結果を再びメッセージストリームに戻す責務を担う。
簡潔に区別すると:
QueryEngine:セッション全体を管理する。
query メインループ:一回または複数回のモデル-ツールループを管理する。能力層:Tools / Commands / Services
能力層は 3 つに分類される。
1 つ目は Commands。スラッシュコマンドとローカルコマンドを処理する。ユーザー入力の中にはモデルによる推論を必要とせず、ローカルで直接実行したほうが安定するものもある。
2 つ目は Tools。モデルが呼び出せるツール機能(ファイル読み取り、ファイル編集、Shell 実行、コード検索、エージェント呼び出し)を処理する。
3 つ目は Services。MCP、LSP、プラグイン、リモートセッションといった外部統合や拡張機能を担う。
これら 3 種類の能力が、Claude Code の実行層を構成している。
コンテキスト層:context、memory、compression
コンテキスト層が答えを出す問いは次の一つである:
このターンで、いったい何をモデルに送るべきか?これは単なる文字列連結ではない。現在のタスク、過去のメッセージ、プロジェクトルール、ユーザールール、ツール説明、MCP の能力、Skill の説明、ファイル読み取り結果、圧縮サマリーを総合的に組み立てる処理である。
Claude Code が「プロジェクトを理解している」ように見える理由もここにある。モデルが生まれつき理解しているのではなく、コンテキスト層がプロジェクトに関連する情報を継続的にモデルへ組み込んでいるのだ。
状態層:AppStateStore
AppStateStore はグローバルな状態を管理する。
ここが管理するのは UI の状態だけではない。
- 現在のモデル設定
- ツール権限のコンテキスト
- MCP クライアントとツール
- プラグインの状態
- サブ Agent / Task の状態
- リモートセッションの状態
- ユーザー設定
状態層がなければ、Claude Code が「端末アプリケーション」と「Agent ランタイム」を統合することは難しい。
セキュリティ層:permissions、sandbox、audit
セキュリティ層はコード上で単一のファイルに集約されるものではなく、ツール実行、権限判定、コマンド分類、MCP 呼び出し、ユーザー確認、セッション記録を横断して存在する。
その本質は、モデルの自由な意図を、統制の効いた実行リクエストに変換することにある。
モデルが「何をしたいか」を伝える
システムが「それができるか」を判定する
ツールが「ルールに従って」実行する
ログが「何をしたか」を記録するこれこそが、本番レベルの Agent とデモレベルの Agent の違いだ。
ソースコードにおける構造ファイル:まずは梁(はり)を数本読む
この章をソースコードリーディングに落とし込むなら、最初に見るべきはすべてのディレクトリではなく、数本の構造ファイルだ。
QueryEngine.ts はセッション層である。ここで重要なのは「すべてを直接こなす」ことではなく、一回の conversation でターンをまたいで保持すべきものを束ねている点だ。メッセージ履歴、権限拒否の記録、ファイル読み取りキャッシュ、モデル設定、ツール群、MCP クライアント、Agent 定義、AppState の読み書き口。毎回の submitMessage() は、同じ conversation のなかの新しい 1 ターンにすぎない。
query.ts はループ層である。反復ごとの State を管理し、messages、toolUseContext、autoCompactTracking、turnCount、pendingToolUseSummary といった状態を次の反復へ引き継ぐ。モデルがストリーミングで結果を返すとき、アシスタントメッセージに含まれる tool_use ブロックを収集する。ツール呼び出しがなければ終了し、ツール呼び出しがあればツールを実行し、結果をメッセージに追記してループを継続する。
Tool.ts はアクションプロトコル層である。ツールとは単なる関数ではなく、一つのプロトコルだ。入力スキーマ、呼び出し方法、読み取り専用かどうか、並行実行の安全性、破壊的操作かどうか、権限の要否、結果のサイズ、UI 表示、エラー時の差し戻し方法など、すべてを宣言しなければならない。モデルが出力するのは「好きに動きたい」という意図ではなく、「このツールプロトコルに従ってリクエストを発行する」という行動なのである。
tools.ts と services/tools/toolExecution.ts は、ツールメニューと実行ライフサイクルを担う。前者はそのターンでモデルが参照できるツールを決定し、後者は個々のツール呼び出しがスキーマ検証、ツールレベルの入力検証、権限チェック、フック、実実行、結果のシリアライズという一連の流れをどう通過するかを決める。
context.ts、constants/prompts.ts、services/compact はモデルの作業台だ。システムルール、プロジェクトメモリ、Git 状態、ツール説明、履歴メッセージ、ツール結果の予算、圧縮サマリといった情報が、各ターンのモデルリクエストにどのように組み込まれるかを決定する。
したがって、ソースコードリーディングはまず次の一文に圧縮できる。
QueryEngine がセッションを管理し、query.ts がループを回し、Tool が行動の境界を定め、Context/Prompt がモデルの作業台を整える。このラインが立った後であれば、MCP、Skill、Agent、Plan を読みに行っても、それらが散逸した機能点には見えなくなる。これらはいずれも、この主線に接続された拡張なのだ。
5. 3層アーキテクチャを統合して捉える
ここまでの内容をひとつの全体像にまとめる。
機能アーキテクチャが示すのは、Claude Code は単なるモデルではなく、モデルを中心に構築された能力システムであるということだ。
Model API
-> QueryEngine
-> Tools / Context / Memory / State
-> MCP / LSP / Skills / Agent 協調
-> セキュリティガバナンス実行アーキテクチャが示すのは、ユーザーの一言はそのままモデルに渡されるのではなく、常時稼働する Agent Runtime に投入されるということだ。
ユーザー入力
-> QueryEngine によるコンテキスト組み立て
-> Model API による判断
-> Tools による実行
-> 結果の還流
-> QueryEngine が次のラウンドへ継続コードアーキテクチャが示すのは、ソースコードを読む際に以下のレイヤーから入り口を探せるということだ。
エントリレイヤー:cli.tsx / main.tsx
インタラクションレイヤー:REPL / 端末 UI
オーケストレーションレイヤー:QueryEngine / query
機能レイヤー:Tools / Commands / Services
コンテキストレイヤー:context / memory / compression
状態レイヤー:AppStateStore
セキュリティレイヤー:permissions / sandbox / auditつまり Claude Code の本質は「モデルといくつかのツール」ではない。それは——
モデルを中心に構築された、拡張可能で、ガバナンスが効き、持続的に稼働する Agent Harness である。
Harness(エンジニアリングフレーム)という比喩は的確だ。モデルは知能を提供し、Harness は実行環境を提供する。モデルがなければシステムに推論能力はなく、Harness がなければモデルは安定してタスクを遂行する能力を持たない。
6. メインフロー早わかり
Claude Code のアーキテクチャにおけるメインフローだけを掴みたいなら、以下のポイントを押さえておけば十分だ。
- Claude Code はチャットボックスではなく、CLI 形態の Agent Runtime である。
- Model API は推論の中核だが、それ自体が現実世界のアクションを直接実行するわけではない。
- QueryEngine がメインループであり、ユーザー入力・モデルの応答・ツール呼び出し・状態変化を一連の流れとしてつなぎ合わせる。
- Tools システムは実行層だが、個々のツールは必ず契約・権限・結果のシリアライズを経由する。
- Context Engineering とは、単に長大なプロンプトを書くことではなく、コンテキストを動的に組み立てることである。
- AppStateStore によって、CLI UI・セッション状態・ツール状態・Agent 状態が協調動作する。
- MCP・LSP・Skills は拡張層であり、Claude Code があらゆる機能を内部にハードコードしなくて済むようにしている。
- セキュリティ層が、Agent をデモから本番のエンジニアリング環境へ持ち込めるかどうかの分かれ目となる。
次回はさらに深掘りする。QueryEngine がこの対話メインループを具体的にどう実装しているのか、そしてモデル呼び出し・ツール実行・コンテキスト圧縮をどのように一本の復元可能なステートマシンへと束ねているのかを見ていく。